Haste.
I guess people call these types of posts “post mortems.” Here we go.
I got this email this morning:

I generally don’t trust alerts with 100% confidence, so I started to check on it. It was weird: it was responding to pings and establishing TCP connections, but it wouldn’t respond to anything. SSH wouldn’t work either.
I disabled and enabled its ethernet port from the switch. It didn’t fix it.
The next step was to give it a power cycle. I can do that remotely with a switched PDU. I think buying that was a great investment. It’s incredibly annoying to drive over to the data center to push a button, and I figured it wouldn’t be practical for me to do it when I’m down in Charlottesville for college.
By this time, I’m thinking that I have no way of fixing it from home, so I need to go on-site.
As I get ready and head to the DC, I think about the worst case scenario. It couldn’t be a kernel panic or weird, horrific hardware failure since Haste obviously was able to boot up and get assign itself the right IP address. It’s probably something software related.
I got there and plugged in a monitor and noticed it wasn’t responsive. I gave it another power cycle. Now, what happened next surprised me a lot.
As it started booting up, I saw the stream of green [OK]s, as expected. Then I noticed OOM (out of memory) errors, and exim (a mail transfer agent) kept getting killed. Out of memory?!
Now, I know for sure that Haste had plenty of RAM for its normal operation. It’s a cPanel server, and 4 GB is plenty. It usually uses < 1 GB. Well, at least I found out what the issue was. It needs more RAM.
Bitcable also hosts VMs, and my #1 priority is to keep VMs up and running as reliably as possible. With that in mind, I have a spare VM host, Storm, in the cabinet. It doesn’t do much – I use it sometimes to experiment with network configurations without touching hardware with customers. The great thing about Storm is that it’s an exact copy of the other servers. Should anything go wrong with the others, I can simply do a hard drive swap and everything should be fine.
Storm had 16 GB of RAM. Haste had 4. Besides those, the two are exactly the same. So I swapped hard drives. It worked, except for the networking. They don’t have the same MAC addresses.
I figured I didn’t know how cPanel handled MAC address changes, and it might be a bad idea to change hardware like that, so I ended up swapping the RAM. After 1 hour and 51 minutes of downtime, everything was back up.
Here’s what Haste’s memory usage looks like right now:
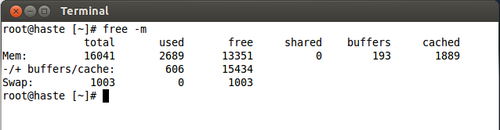
Again, an OOM event is really unexpected.
So what in the world caused that out-of-memory issue? Was it perhaps a DOS vulnerability? Did cPanel explode on me? Unfortunately, it looks like I didn’t add Haste to my Observium setup (doh!). But, would that have helped? Observium polls SNMP counters every 5 minutes. And it doesn’t even track processes. It wouldn’t have been useful, in my opinion.
The issue right now isn’t that there was downtime. The issue is that something bad happened and I have no idea why. Maybe I need a high-resolution monitoring system to help diagnose issues like this! ;)
Lessons learned (or reiterated):
- Spares are really, really helpful.
- Physical hardware is annoying. Isolating this to a VM would mean all of this hardware swapping nonsense wouldn’t be an issue.
- Remotely manageable hardware is also really, really helpful.
- High resolution monitoring is a must.
