SketchRank: Faster Ranking with Sketches
For the past few years I’ve been writing and speaking about time-series storage, a problem inspired by what I help build at VividCortex and also my personal projects. I’ve been thinking about a related problem for much longer, but I haven’t had to work on it until now: ranking.
At VividCortex, we have a new tool called the Profiler. It allows you to rank within various categories of metrics, like MySQL or OS metrics, by a dimension, like count. You can rank top processes by total CPU time or memory, MySQL queries by execution time, and so on. We can do this for arbitrary time ranges.
The ranking is performed on the sums of values within each time range. If we’re ranking by CPU usage during a 300 second window, we look at the CPU usage measurements for each process at every second, sum those values up, and then rank them in descending order. At the end we get a list of processes that are ranked by total CPU usage.
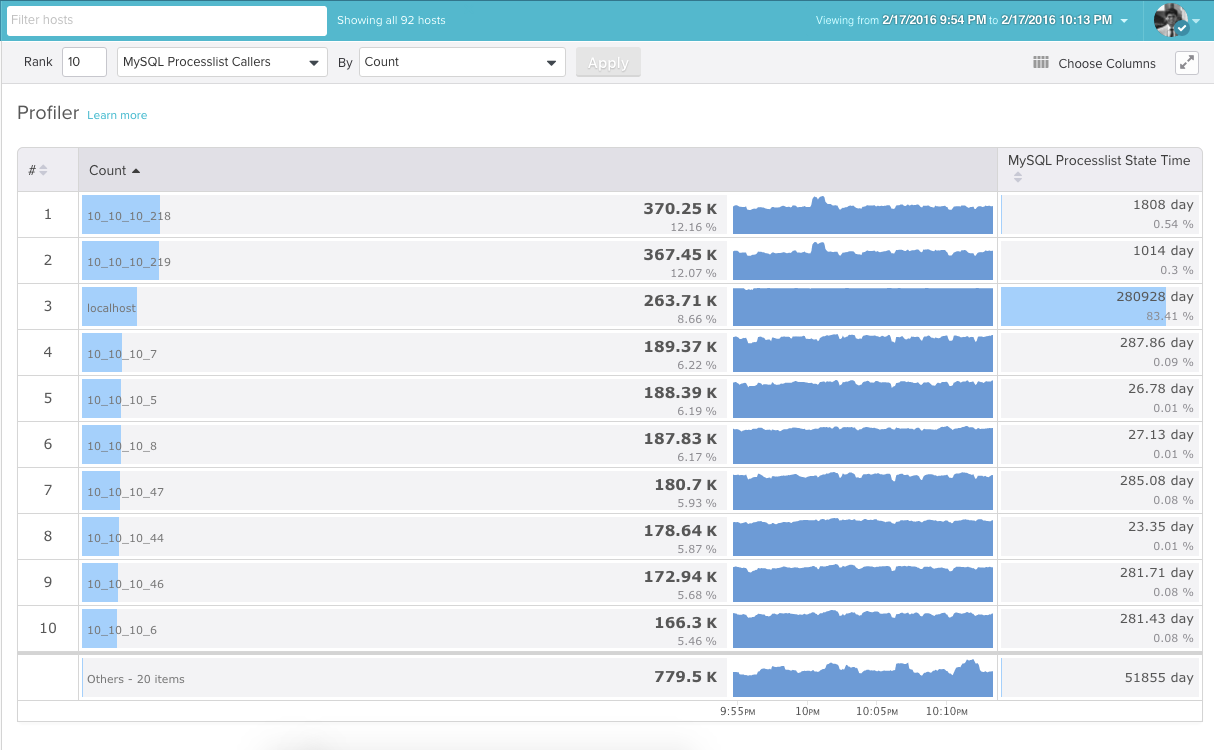
Here’s a screenshot showing the top 10 MySQL Processlist Callers ranked by count. These are simply hosts and counts. You could think of these values as requests per host.
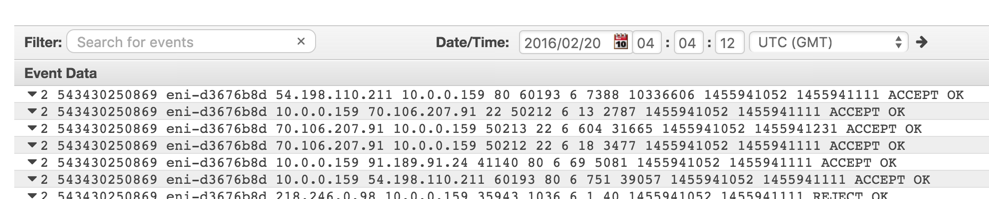
You can do this sort of ranking for anything. You may be looking at things like TCP flow logs from AWS and want to rank TCP connections by the number of packets transmitted.
The difficulty with ranking is that you have to do lots of summing and sorting depending on the number of metrics you need to consider, and there aren’t obvious optimizations you can make to speed things up. Considering arbitrary time ranges to do the ranking means it may not be worth it to precompute some data. Finally, especially in my cases, rankings have to be correct. We don’t want to see entries that don’t belong in the final ranking, and we certainly don’t want to miss those that do.
One technique we thought about was pre-ranking. We wanted to see if we could take 1-minute time ranges, generate ranks within each range, and somehow aggregate those rankings together. We quickly found out that this doesn’t work because we’re considering sums for the rankings.
| Timestamp | Rank 1 | Rank 2 |
|---|---|---|
| 1 | A = 3 | E = 2 |
| 2 | B = 4 | E = 2 |
| 3 | C = 1 | E = 0 |
| 4 | D = 2 | E = 1 |
When you calculate the sums in this time range, you’ll see that the top element is E, but it was never in the top position in any of the individual timestamps. After realizing this issue, we concluded that we can’t avoid summing and ranking in order to get the correct results.
Approximating with a sketch
I wrote that ranking has to be correct, so how can approximations help? Approximations allow you to process data in multiple passes, and we’ll use a sketch to do most of the ranking work really quickly.
First, you’ll have to create a hash for each entry. Just like a bloom filter and a count-min sketch, the hashing method used will determine the maximum capacity of the sketch and its accuracy. With enough unique hash values the sketch becomes redundant since it stops approximating, and you’ll get a similar result in the other extreme.
The following uses a simple modulus operation on the IP address to generate a hash:
| Address | Hash |
|---|---|
| 10.0.0.1 | 1 |
| 10.0.0.2 | 2 |
| 10.0.0.3 | 3 |
| 10.0.0.4 | 4 |
| 10.0.0.5 | 5 |
| 10.0.0.6 | 6 |
| 10.0.0.7 | 7 |
| 10.0.0.8 | 0 |
| 10.0.0.9 | 1 |
| 10.0.0.10 | 2 |
| 10.0.0.11 | 3 |
Next, generate time series for the hashes. For the value, use the maximum of the values that
correspond to each particular hash. For example, if 10.0.0.1 has value 5 and 10.0.0.9 has 3,
use 5.
| Timestamp | Hash | Value |
|---|---|---|
| 1 | 1 | 5 |
| 1 | 2 | 4 |
| 1 | 3 | 9 |
| 1 | 4 | 2 |
| 1 | 5 | 8 |
| 1 | 6 | 4.5 |
| 1 | 7 | 3 |
| 1 | 0 | 1 |
| 2 | 1 | 1 |
| 2 | 2 | 3 |
| 2 | 3 | 4 |
Algorithm
Let’s say you wanted to get the top address at timestamp 1. In practice you’d probably be looking
at a range of timestamps. The normal way to do this would be to look at all of the values for each
address present at timestamp 1, sort them, and pick out the top one. Note that you can do this
online (i.e. in one pass) because there is no summing going on, but you can’t if you need to
consider a range!
When you use the sketch, you’re going to do the same operation, but this time you’re going to get
a different result. Instead of getting the top address, you’ll get the top hash. Using the example
data in the table above, you will get hash 3, which corresponds to the addresses 10.0.0.3,
10.0.0.11, and so on. Finally, you’ll perform the same operation as in the previous method
except you’ll only be looking at a subset of the addresses.
Does this make a difference? Depending on your parameters, it can make a huge difference in terms of how many rows you need to look at in your database. In our case, I think we can reduce the number of rows considered by an order of magnitude.
I don’t have any good benchmarks or test results to share since this is still something we’re working on and it’s in its early stages. Based on what I’ve seen in my initial experiments and fights with the MySQL optimizer, I’m expecting a 7x improvement in ranking performance. Hopefully we’ll pull it off because that’ll be a pretty awesome thing to share.
