Reliable Broadcast
Reliable broadcast is a fascinating introduction to distributed systems. The goal is simple: to reliably propagate a message across a cluster of nodes such that all nodes receive the message and process it exactly once. “Reliably” means that it should work even if the connections between nodes are faulty.
Broadcast
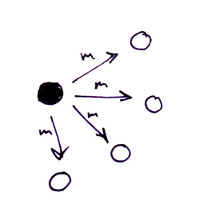
To understand why a reliable broadcast is necessary, you first have to know the simple broadcast algorithm, which is shown in the following sketch. A broadcasted message m sent by one node gets replicated and sent to every other node in a cluster. An example of the broadcast algorithm used in practice is ARP, which is something I’ve written about before.
The following sketch shows a broadcasted message m with a partition separating one of the nodes from the sender. The red node can’t receive messages from the sender so it fails to process m.
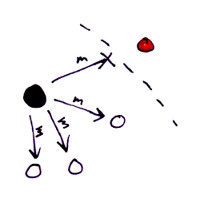
It may be the case that only the broadcaster and the red node have a broken connection, and the rest of the nodes of the cluster have no problem sending messages to the red node. If we still want all nodes to receive m, the simple broadcast algorithm is not good enough.
Reliable broadcast algorithm
The reliable broadcast extends the simple broadcast to work even if some of the links between nodes are faulty. There are many different implementations, but here’s one example. The only difference between a regular broadcast and this reliable broadcast is that receivers rebroadcast a message if they see it for the first time.
func Broadcast(m Message) {
SendToAllNodes(m);
}
func Receive(m Message) {
if !previouslyProcessed(m) {
// First time this Message was received.
// Broadcast it again.
Broadcast(m);
// Process the message.
Process(m);
}
}
The following sketch shows a reliable broadcast. I didn’t draw all of the message paths visible for simplicity. As long as there is a path from one node to another, a message will be delivered.
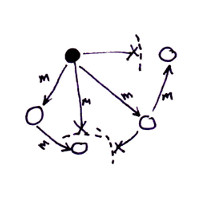
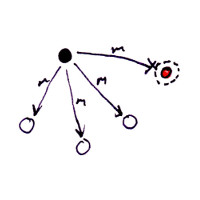
The only case where a reliable broadcast doesn’t deliver a message to all nodes is when certain nodes are completely disconnected from all of the other nodes. It’s impossible for all nodes to receive m in this case.
Implementation question: previously seen?
Something that I’m not quite sure about is how the previouslyProcessed function is implemented. How do you check if a message has been received or processed before? You could give each message a unique ID or hash, and keep track of all of the IDs that have been processed. Clearly this would require unbounded storage over time as more and more messages get reliably broadcasted.
Perhaps the answer to this question is to simply discard all but the K most recent messages, but that worries me since it may get tricky to guarantee that messages only get processed once! Maybe a timestamp encoded into the ID would help, but time is even trickier to handle.
Atomic broadcast
Atomic broadcast is an extension to the reliable broadcast protocol that satisfies a total order property. In other words, this means that messages are “received reliably and in the same order by all participants.” This property is quite useful for building replicated state machines because each message can represent some sort of state transition. Because all messages are reliably delivered in order, all nodes receive the same state transitions and therefore reach the same, replicated state.
Here’s a neat fact: it has been shown that atomic broadcast and consensus are equivalent. If you know about consensus, you know that it is a hard problem, and should give you a hint to the complexity of its twin. Because consensus has already been solved by Paxos and Raft, among others, atomic broadcast gets a lot simpler to think about and implement.
Building distributed systems requires reliable message propagation and delivery, and reliable broadcast gives us a method to do so. I think it’s is one of the most elegant algorithms I’ve come across. It’s simple enough to visualize and understand, yet provides such a powerful guarantee that serves as a building block for atomic broadcast and consensus.
